承接著爬蟲,大家或許對於爬下來的資料如何儲存還是會有一點疑惑,當然最簡單的方式其實就是存成txt檔,不過讀檔出來時就可能會遇到一些障礙。進階一點,你可以選擇json檔,不過如果檔案不小的話,資料尋找可能會有效率層面的問題。所以整體而言最好的選擇,其實還是資料庫。因此,以下介紹一款,我個人比較喜歡使用的資料庫MongoDB。
MongoDB作為一樣輕便、免費的選擇,其熱門不是沒有道理,以下就讓我們來一探究竟。要使用MongoDB主要有兩個方案,第一直接使用本機端的資料庫,第二使用雲端的資料庫,當然兩者各有利弊,而這篇文章中,都會介紹使用級操作方式。
我們來稍微比較一下,本機端MongoDB跟雲端MongoDB的差異。本機端的MongoDB讀寫速度較快,畢竟不需要經過跟遠端server互動的過程,雲端的話相對會慢一些;但是因為本機端只有你自己的電腦連線的到,如果要跟隊友共享資料,那就會比較麻煩,可能必須經過一些輩分復原的程序,把你的檔案複製到它的電腦上(如非你可以把自己的電腦架設成為server),但是雲端的話,你只要開一個使用者權限給她,隊友只要有辦法上網,就可以存取裡面的資料。
| 方案 | 本機端 | 雲端 |
|---|---|---|
| 連線速度 | 快 | 慢 |
| 共享資料 | 麻煩(備份程序) | 簡易(權限更改) |
註: 關聯式與非關聯式資料庫我在第二天的文章中就有介紹過,這邊就不再多嘴。
由於別人在這個部分已經寫得很完整了,可以參考這一篇文章。因此,這個部分我就跳過了。我覺得其中比較需要注意的是:
這東西算是mongodb的視覺化操作介面,安裝好之後,就會跳出如下頁面,請按create,然後把new connection改成local(看你本機端的聯想想要叫什麼明子都可以)。只要你的server有跑起來,應該就可以成功建立連線,這個前端app就會連接到你的mongodb server。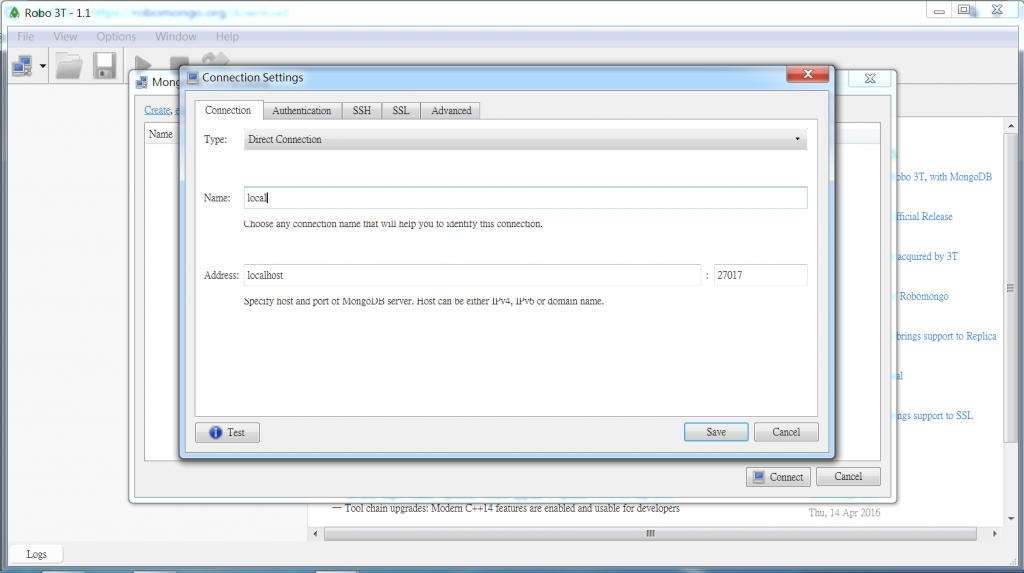
這個時候你可以用右鍵去點擊你的連線,選擇Create DataBase,然後自己命名,然後再創造好的Database上面雙擊,應該可以看到一個資料夾叫做collection,右鍵點擊後選擇Create collection。這個時候你已經把資料庫跟文章集創造完成。
這邊稍微說明一下,這分別是時麼意思,collection其實就是一張table,而之所以會稱為collection的原因是,NoSql資料庫本來是開發來支援文件檢索功能,所以一筆資料(json中的一個dict,也就是table中的row)就會被當作一篇文章及其metadata(描述文章的資料),而很多個文章組成的及合稱為文章集,也就是collection。而很多個collection當然就組成一個database啦。最後,也可以想像一個server上面可以存放很多個database。總而言之,同整如下:
| SQL | NOSQL |
|---|---|
| server | server |
| database | database |
| table | collection |
| row | dictionary |
這個地方我的習慣是使用mlab的服務,畢竟它沒有超過0.5G就不用付錢,很多服務加上其實不會超過這個大小,所以也就選擇了它。由於申請帳號的過程太簡單,我就略過啦。不過要提醒大家一點的事情,當帳號申請好,也創建好資料庫,要千萬記得一件事情,就是進去user的地方創建一個user。
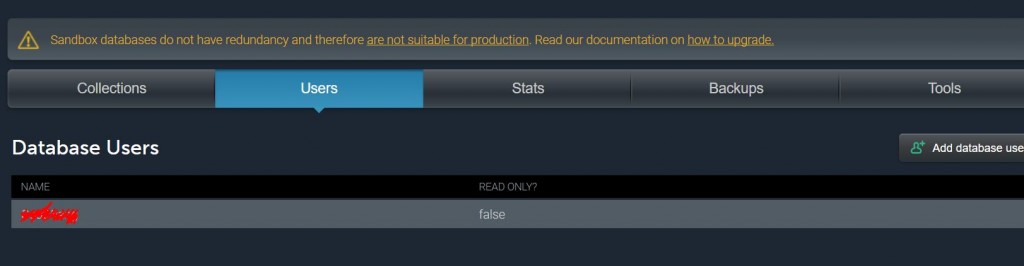
創建完user之後,你就可以透過Robo3T去連線啦,不過這邊的連線方式比較複雜,請一步步填入以下資訊:
python跟MongoDB的互動主要是透過pymongo來完成,接下來將會逐一說明連線(MongoClient)、尋找(find)、插入(insert)以及刪除(delete)在python中的實踐。另外,因為創建Database跟collection,Robo3T的GUI便可以輕而易舉的完成,其實不太需要硬是要透過程式碼來完成,所以這邊就不交代了。
# import
from pymongo import MongoClient
from bson.objectid import ObjectId #這東西再透過ObjectID去尋找的時候會用到
# connection
conn = MongoClient("<url>") # 如果你只想連本機端的server你可以忽略,遠端的url填入: mongodb://<user_name>:<user_password>@ds<xxxxxx>.mlab.com:<xxxxx>/<database_name>,請務必既的把腳括號的內容代換成自己的資料。
db = conn.<database_name>
collection = db.<collection_name>
# test if connection success
collection.stats # 如果沒有error,你就連線成功了。
#尋找一筆資料
cursor = collection.find_one({'<column_name>': '<what_you_want>'})
cursor = collection.find_one({'_id': ObjectId('<id_string>')}) #如果你在意速度的話用Id尋找會比用內容尋找快很多喔!
#回傳全部資料
cursor = collection.find({}) #此處須注意,其回傳的並不是資料本身,你必須在迴圈中逐一讀出來的過程中,它才真的會去資料庫把資料撈出來給你。
data = [d for d in cursor] #這樣才能真正從資料庫把資料庫撈到python的暫存記憶體中。
#尋找全部資料
cursor = collection.find({'<column_name>': '<what_you_want>'})
如果大家對於更進階的檢索有興趣,例如說如何尋找Null值,或是如何模糊比對出某一字串,我個人比較少用到(還是有用過啦),就請大家自行做功課摟。(補充: 如果大家的資料量沒有大到很誇張,其實可以都全部讀進Python中的暫存,再來處理)
# 刪除一筆資料
collection.delete_one({'<column_name>': '<what_you_want>'})
# 刪除全部資料
collection.delete_many({})
# 刪除多筆資料
collection.delete_many({'<column_name>': '<what_you_want>'})
# 插入一筆資料: 請放入一個dict
collection.insert_one(<to_be_insert_dict>)
# 插入多筆資料: 請放入一個dist
collection.insert_many(<to_be_insert_dist>)
原本明天想發的文章是MongoDB的備份,但是後來想想其實實用性不高,加上寫到後面的文章時不太順利,發現應該要先交代pandas才能讓大家比較好的理解我在幹什麼,所以接下來三天,應該會很細緻的介紹pandas。pandas可以說是python中的excel,功能非常強大,如果還沒機會接觸,非常建議可以跟著一起玩一下,一定會有所收穫。



 iThome鐵人賽
iThome鐵人賽